
Zero-shot text-to-video generation. We present a new framework for text-to-video generation with exceptional spatial-temporal dynamics, featuring realistic object movements, transformations, and background motion within the generated videos.
We present FlowZero, a framework for text-to-video generation that leverages the spatio-temporal reasoning capabilities of Large Language Models (LLMs) to guide image diffusion models. At its core, FlowZero features the Dynamic Scene Modeling Engine (DSME), which combines a structured representation called Dynamic Scene Syntax (DSS) and an iterative self-refinement mechanism. DSS encapsulates frame-level scene descriptions, object layouts, and background motion patterns. By using DSS, the framework enables precise modeling of spatio-temporal dynamics including object trajectories and semantic scene evolution derived from textual prompts. The iterative self-refinement mechanism further ensures spatial and temporal coherence by aligning generated layouts with input descriptions across frames. Additionally, a motion-guided noise shifting technique enhances global background consistency, leading to smoother and more realistic video synthesis. Extensive experiments, including qualitative, quantitative, and ablation studies, demonstrate that FlowZero produces high-quality, dynamic videos aligned with complex textual prompts. The generated videos effectively showcase directed object motions, semantic transformations, and complex object interactions, all without requiring additional video-specific training data.
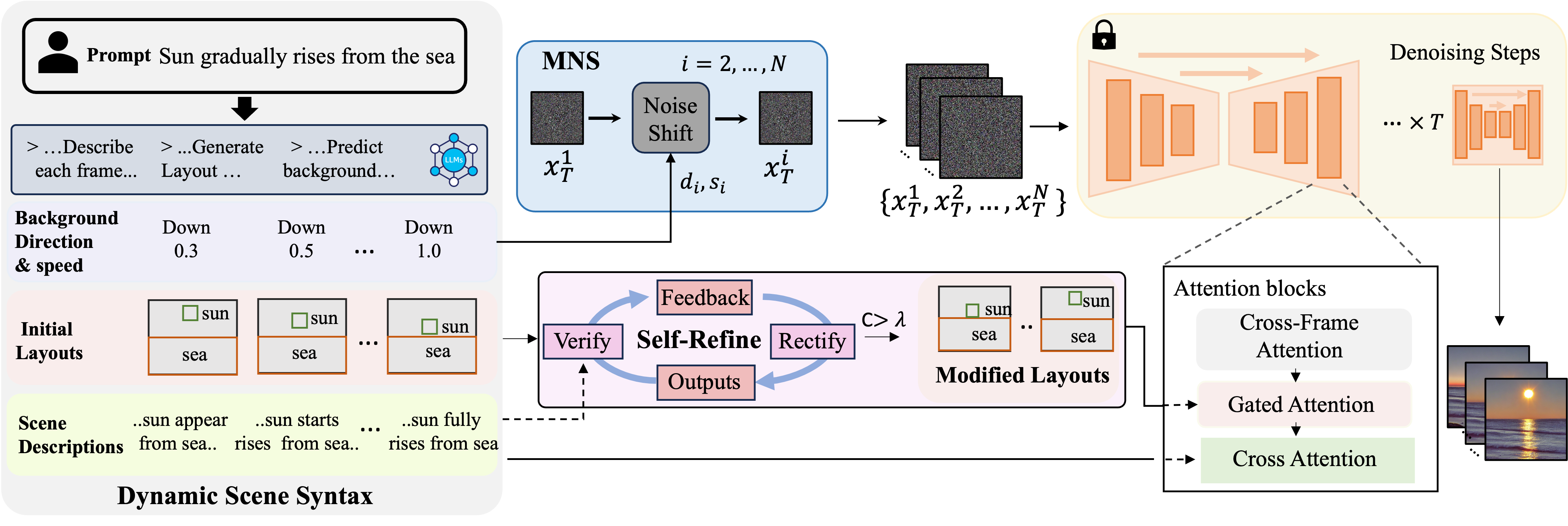
Overview of FlowZero: Starting from a video prompt, we first instruct the LLMs (i.e., GPT4) to generate serial frame-by-frame syntax, including scene descriptions, foreground layouts, and background motion patterns. We employ an iterative self-refinement process to improve the generated spatio-temporal layouts. This process includes implementing a feedback loop where the LLM autonomously verifies and rectifies the spatial and temporal errors of the initial layouts. The loop continues until the confidence score \(C\) for the modified layouts exceeds a predefined threshold \(\lambda\). Next, we perform motion-guided noise shifting (MNS) to obtain the initial noise for each frame \(i\) by shifting the first noise with predicted background motion direcction \(d_{i}\) and speed \(s_{i}\). Then, a U-Net with cross-attention, gated attention, and cross-frame attention is used to obtain \(N\) coherent video frames.
 |
 |
 |
|
| "A butterfly leaving a flower" | "A horse is running from right to left in an open field" | "A caterpillar is crawling on a branch, and then it transforms into a butterfly, then it flies away" | "A man and a woman running towards each other, and hugging together" |
 |
 |
 |
 |
| "sun rises from the sea" | "Three birds flying from right to left across the sky" | "A volcano first dormant, then it erupts with smoke and fire" | "A man is waiting at a bus stop, and after the bus arrives" |
 |
 |
 |
 |
| "A jogger is running in the field, then a dog joins him" | "A panda is climbing the tree from bottom to top" | "Ironman is surfing on a surfboard in the sea from left to right" | "A soccer player kicks a ball towards another player" |
 |
 |
 |
 |
| "A bird rests on a tree, then fly away" | "A balloon floats up into the sky" | "A plane ascends into the sky" | "A girl is reading a book in a garden as two butterflies flutter in the side and a cloud moves across the sky" |
If you use our work in your research, please cite our publication:
@article{flowzero,
title={FlowZero:Zero-Shot Text-to-Video Synthesis with LLM-Driven Dynamic Scene Syntax},
author={Yu Lu, Linchao Zhu, Hehe Fan, Yi Yang},
journal={arXiv preprint arXiv:2311.15813},
year={2023}
}